
For a while, the AI landscape was like the Wild West: the internet has no borders, so why would AI? If data existed online, developers treated it as free for the taking. Huge datasets were scraped with little regard for language or national boundaries, all in the name of building one-size-fits-all models.
That era is now over. And it’s not because companies suddenly grew a conscience, but because the law caught up. From the EU’s AI Act to China’s PIPL, along with new regulations across the Middle East, governments are forcing a rethink of how AI is built and deployed.
Companies building global AI now have to treat multilingual data, and language itself, as a strategic, regulated asset.
Why Language Now Sits at the Heart of AI Compliance
Since the emergence of ChatGPT, the dominant approach of leading-edge AI companies has been centralization. They collected data from everywhere—French blogs, Chinese social media, American news sites—and dumped it all into one massive cloud server, usually in the United States.
This was all about efficiency. Put everything into one bucket, mix it together, and intelligence comes out the other end. But that logic is now starting to fall apart with new regulation focusing on sovereignty and data quality.
On the sovereignty side, countries are saying, “Our data is a national asset.” At the same time, regulators are saying, “Your AI systems are making decisions that affect people’s lives, so the data behind those decisions needs to be accurate and appropriate.”
Because meeting those expectations ultimately depends on how well AI handles local language and context, language now sits at the heart of AI compliance. A main catalyst for this is the European Union’s AI Act, which came into force in 2024 and is widely seen as the blueprint for this new regulatory era.
One of the most important parts of the Act is Article 10. It requires that training datasets for high-risk AI systems be representative and as free from errors as possible.
That word “representative” matters a lot in a legal context. It’s not optional. If you’re building AI for things like hiring or education—systems the EU classifies as high risk—you can’t just train them on generic internet data.
On top of lacking specialization, generic internet data is heavily skewed toward American English. If your AI doesn’t understand a cultural reference or a regional way of speaking, and that misunderstanding causes a job applicant to be rejected or penalized, that’s now illegal under EU law. The penalties can be severe, including multimillion‑euro fines and forced fixes.
In effect, a failure to understand language context becomes a form of discrimination. It creates systemic bias, and companies are legally responsible for that.
This forces organizations to adopt much more sophisticated data governance practices. They have to document their process, run bias detection checks, and prove that their data reflects the specific geographic and cultural context where the AI is being used. You can’t just deploy a model trained in California into Paris and hope it works.
Data Sovereignty Is Reshaping Multilingual AI Architectures
There’s another dimension that makes this even more interesting: geography.
This is what is meant by digital sovereignty, the principle that a country has the right to control data generated within its borders. Data is treated like a strategic resource, similar to oil or gold.
The clearest example of this is China, where regulatory framework is especially strict. It’s built around laws like the Personal Information Protection Law, or PIPL, and the Data Security Law, often called the DSL.
Yes, it’s an alphabet soup of regulation. But the practical impact is clear. If you’re a global company, you can’t simply take Chinese legal documents or citizen data and feed it into a large language model hosted abroad. Doing that triggers China’s cross-border data transfer rules. You may need formal security assessments from the Cyberspace Administration of China. In some cases, you’ll need approved contractual clauses just to move the data at all. You may need formal security assessments from the Cyberspace Administration of China. In some cases, you’ll need approved contractual clauses just to move the data at all.
And if you get it wrong, the consequences are serious. Contracts can be invalidated and companies blacklisted. In extreme cases, you can effectively be pushed out of China’s digital market entirely.
And this isn’t limited to China. The Middle East is becoming a major force in AI, and similar ideas are taking hold there as well.
Countries like the UAE and Saudi Arabia are promoting what they call PDPL-compliant architectures, PDPL standing for Personal Data Protection Law. The basic rule is simple: if you’re handling sensitive data, it needs to stay in the region. That means using cloud infrastructure located within the Gulf Cooperation Council, or GCC.
For companies building global AI, this represents a major shift. The old model was to build one giant “brain” in the cloud and let everyone connect to it. Now that model is breaking, because data increasingly has to stay where it’s created.
This shift has given rise to a new concept: sovereign AI.
Countries want independence. They don’t want their critical digital infrastructure to depend on foreign governments or foreign companies.
In Europe, 62% of organizations are now actively looking for sovereign AI solutions specifically to reduce geopolitical risk. The thinking is that if political relationships change, you don’t want another country to be able to switch off your intelligence infrastructure.
As a result, nations want AI “factories” inside their own borders. That’s why companies like Mistral AI in France or cloud providers like Delos in Germany are gaining momentum. They offer localized AI: models trained domestically under local laws.
In this new world, intelligence isn’t just something you build. It’s something you govern at home.
The Shift to Region-Aware, Governance-First Language Workflows
There’s a bigger question underneath all of this: does this new approach to governance actually make AI better, or are we just adding layers of bureaucracy? After all, fragmentation usually hurts performance.
The answer is yes—it does make AI better. Because in practice, “one-size-fits-all” usually means “one-size-fits English speakers.”
Look at Llama 3.1, a large, state-of-the-art opensource model. While its performance in English is strong, performance in smaller languages like Latvian is more than 25 percentage points lower.
That’s an enormous difference. If you’re a Latvian company using that model, you’re effectively working with a tool that’s 25% less capable than what an American company gets.
And that’s the key point. Many so-called “global” models are really English-first models with translation layered on top. They don’t truly understand local culture or context. What regulation is doing—almost accidentally—is forcing companies to address a quality problem they might otherwise ignore.
That’s why we’re seeing a surge in linguistically native models: AI systems built from the ground up for specific languages and cultures.
Vietnam is a great example, with PhoGPT. The name alone is perfect, but the technology behind it is just as impressive. PhoGPT was trained on over 100 billion Vietnamese words from news, books, and legal documents. Because it’s deeply rooted in the language and context, it delivers stronger results than many much larger global models when working in Vietnamese, even though it isn’t designed to be a direct competitor.
Thailand is following a similar path, driven by the same motivation. This is about cultural preservation just as much as performance. If everyone relies on American trained models, over time people start writing, thinking, and expressing ideas in ways shaped by those models. Local AI helps protect linguistic nuance and cultural identity.
But this raises a practical concern. If you’re a global bank or multinational company, do you really need to build dozens of separate models for dozens of countries?
Not necessarily. There are smarter technical approaches that avoid turning everything into isolated silos. One of the most important is federated learning.
This method lets the model travel to the data, not the other way around. The AI trains locally, on servers inside each country, using data that never crosses borders.
Once training is done, only the learnings—the mathematical updates to the model—are sent back to the central system. The raw data stays put, but the global model still improves based on what it learned locally.
Think of it as the model summarizing what it learned in the form of math, not content. For example, a general‑purpose language model might refine its sense of which phrasing patterns are common in one region versus another after training on local text data, but it never exposes the text itself. The updates are statistical signals, not sentences, and can’t be reverse‑engineered into the original data.
This is a powerful idea. You get the benefits of scale and shared intelligence, while still respecting data localization and sovereignty laws. From a compliance standpoint, it’s a game changer.
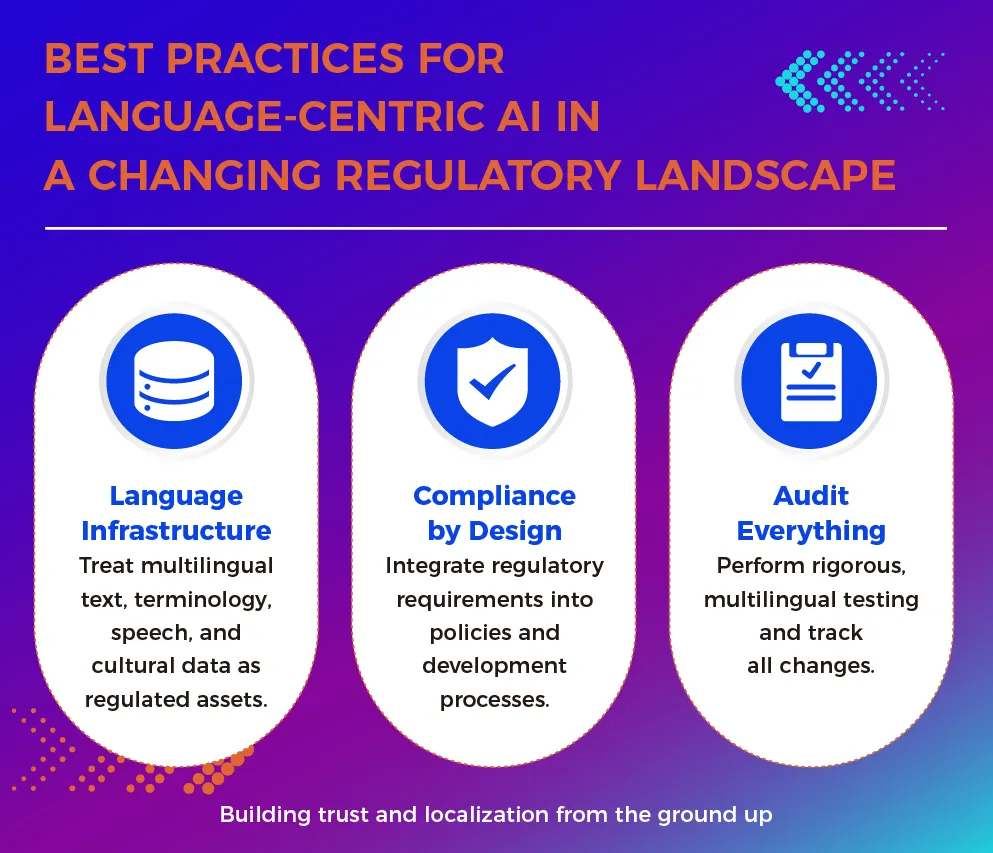
Three Principles for Building Compliant Language Data Systems
It’s now clear that regulation is forcing global AI architectures to become more fragmented and dependent on accurate local language data. For many organizations, this means their existing data pipelines—built for scale rather than scrutiny—now fall short of what modern compliance frameworks demand.
To navigate this shift without chaos, it helps to anchor your strategy in a few foundational practices.
If you’re slightly panicking about your current data strategy, here are three core principles to keep in mind:
- Language infrastructure. Linguistic assets—translations, text data, speech—need to be treated with the same level of care and security as financial data. This isn’t “just words.” Language is risk. And it’s also value.
- Compliance by design. Don’t try to bolt compliance on at the end. Build systems that respect borders and regulations from the start. Architectures like federated learning do this naturally. The rules aren’t an addon anymore—they’re part of the code.
- Audit everything. Bias audits are becoming the equivalent of safety inspections. You wouldn’t fly a plane that hadn’t been inspected. In the same way, you shouldn’t deploy a high-risk AI system without thoroughly auditing it for bias and data quality.
Conclusion
We usually think the most powerful AI is the one that knows the most: the model with the biggest brain, the one that’s read the entire internet.
But in a world shaped by sovereignty and regulation, the most powerful AI may not be the one trained on the most data, but the one trained on data that represents the people it serves.
That’s likely to be one of the defining challenges of the next decade.
Companies now need to understand where their data comes from and what risks travel with it. Compliance becomes not just a legal exercise, but a way of ensuring accuracy and cultural intelligence in the AI products they deploy.
This is where the real work begins. And it’s also where the right partners matter.
Clearly Local helps organizations transform their multilingual data into clean, compliant, AI‑ready assets. No matter where you’re starting, we can help you build the foundations for AI that is responsible and clearly local.
Before you go, take a look at your own data. Do you know where it came from? Do you know where it’s allowed to go? If not, now is the right moment to find out.

