
Key Takeaways:
- Relying on a single AI translation model limits quality, coverage, and flexibility in global localization efforts.
- Multi-model orchestration enables organizations to match the right AI engine to each content type, language, and risk level for better outcomes.
- Companies that succeed globally treat translation as a strategic system—combining multiple models, human expertise, and smart routing—rather than a single tool.
For the past few years, the AI translation conversation has been dominated by one question: which model is best? Teams evaluated, debated, and ultimately committed to a single engine—Google Translate, DeepL, ChatGPT—and built their global content workflows around it.
But with single-provider setups already on the decline, that question is now the wrong one to ask.
The companies outperforming their peers in translation quality aren’t the ones who found the perfect model. They’ve found something more valuable instead: the ability to move fluidly between models, routing each piece of content to the engine most suited for the job.
This multi-provider strategy represents a fundamental shift in how global translation works. If your organization is still anchored to a single-model mindset, you’re leaving quality on the table and accumulating risk you may not fully see yet.
Why One Model Fails at Global Scale
No AI translation model is good at everything. This isn’t a criticism of any particular engine; it’s just the reality of how these systems are built and trained.
DeepL, for instance, is widely regarded as one of the strongest models for European language pairs. In blind evaluations, it outperforms Google Translate on fluency for languages like French, German, and Spanish. But DeepL supports a few dozen languages (mostly focused on Europe).
The moment your content needs to reach audiences in Asia or Africa, that advantage evaporates. Google’s scale of 200+ languages gives it a substantial edge in lower-resource languages. But Google doesn’t match DeepL’s precision for high-nuance European content.
The differences don’t stop at language coverage. Content type matters just as much.
Testing by Lokalise found that Anthropic’s Claude model performed best for brand-sensitive marketing translation, the kind of content where tone and cultural resonance matter more than technical precision. GPT-4o, on the other hand, showed an edge for technical documentation and code localization. And Google’s Gemini model handled very long-context, multi-file translations more reliably than either.
Think about what this means for a global technology company, for example. Their product documentation, marketing campaigns, support content, and legal agreements all require translation—but each of those content types performs differently across models. Routing all four through one engine doesn’t optimize any of them. It just applies one set of strengths and weaknesses uniformly across every task.
There’s also a less visible but serious risk: model instability. AI engines update continuously, and not always for the better. Organizations that have locked into a single provider have watched translation quality shift unexpectedly—sometimes significantly—with no change on their end. One analysis tracked quality across several leading models over just a few months and found meaningful performance drops following engine updates. When your entire translation infrastructure runs through one system, you have no fallback. You’re exposed.
Data governance adds another layer of complexity. Different models have different data policies. For companies handling regulated content, like healthcare documentation and financial disclosures, knowing exactly where your data goes and whether it’s retained isn’t optional. Regulators and internal legal teams increasingly require it. A single-model setup either forces all content through whatever data policy that model offers, or requires laborious manual exceptions. Neither is sustainable at scale.
The Rise of Multi-Model Orchestration
So, what is the solution? Multi-model orchestration. This means having a decision layer that sits above your translation engines and automatically routes each piece of content to the right one, based on rules you define.
Think of it as a traffic controller for translation. Rather than sending every job down the same road, an orchestration layer evaluates what’s coming—language pair, content type, risk level, required turnaround—and directs it accordingly.
Leading platforms are already built around this model. For example, Clearly Local leverages Phrase’s MT AutoSelect feature to dynamically select from multiple MT providers based on content type and target language, enabling smarter routing and up to 3 times higher translation quality than any single engine in isolation.
MachineTranslation.com, takes a different approach: it queries multiple engines simultaneously and displays results side by side. Its SMART translation feature analyzes agreement across engines and surfaces the most consistently supported translation as the most reliable option. For example, when DeepSeek, Qwen, and ChatGPT all arrive at similar phrasing, that convergence carries more confidence than any single output alone.
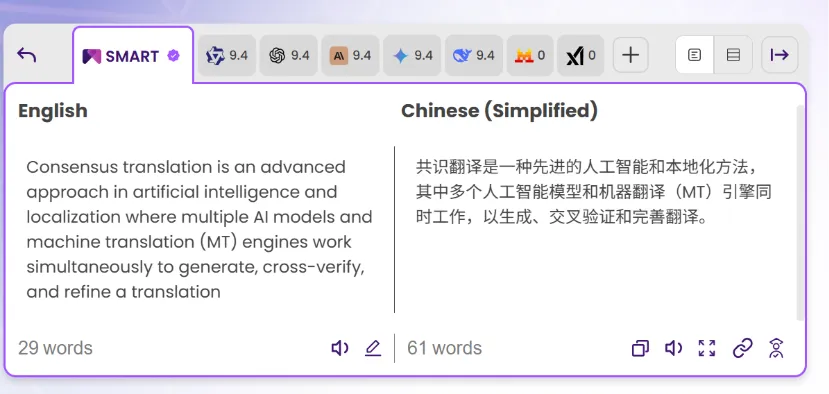
This unique method is known as “consensus translation”. It involves multiple models working in tandem, with the orchestration layer catching what any single engine would miss. Data shows measurable reductions in post-editing effort and improved user satisfaction scores when this approach replaces single-engine workflows.
The pattern across these examples is consistent. The models themselves are inputs. The orchestration layer is the strategy.
Strategic Advantages of an Orchestration-First Approach
The case for multi-model orchestration isn’t just about translation quality, though that alone is compelling. It touches every dimension of how global content operations are managed.
- Quality becomes manageable, not accidental. When you control which model handles which content type, quality stops being a function of luck. High-stakes content—regulatory filings, brand campaigns, executive communications—can be routed to your highest-performing or human-reviewed pipeline. Bulk, low-risk content can move faster through more cost-efficient channels. Quality becomes a design decision, not an outcome you discover after the fact.
- Cost efficiency follows from specificity. A recent comparison of AWS Bedrock models against DeepL found that Anthropic’s Claude Sonnet 3 produced comparable translation quality to DeepL at roughly 28% of the cost per word. Claude Haiku, for lower-complexity tasks, came in at around 4% of the cost. Those numbers are illustrative rather than definitive—costs vary, and performance depends on the use case—but the principle holds: matching model to task reduces your effective cost per good translation. You’re not paying premium rates for content that doesn’t require them.
- Risk exposure shrinks. An orchestration-first setup gives you meaningful insulation from the instability of any single provider. If one engine degrades following an update, traffic shifts. If a vendor changes its pricing or data policies, you have alternatives ready. If regulations change the data handling requirements for certain content types, you can update routing rules without rebuilding your entire workflow.
- Auditability becomes possible. A well-configured orchestration layer logs not just what was translated, but which engine handled it, why it was selected, and what quality signals came out. For enterprises subject to regulatory scrutiny—or simply those that want accountability in their AI use—this kind of traceability is essential.
- Human expertise goes where it’s needed most. Orchestration doesn’t eliminate human review—it makes it more intelligent. Rather than having linguists check every translation, orchestration can flag only the segments with low confidence scores or high-stakes designations. This way human effort concentrates where it has the most impact.
Conclusion: From Tools to Translation Ecosystems
The companies that will lead in global markets over the next five years aren’t going to win because they found a better AI model. They’ll win because they built a smarter system around the models they have—and left themselves room to adapt as those models continue to evolve.
That means evaluating translation platforms not by which single engine they use, but by how well they manage many. It means building routing logic that reflects your actual content risk profile.
It also means acknowledging that this is no longer a set-it-and-forget-it decision. AI translation is a living system. The organizations that thrive will treat it that way—benchmarking continuously, adjusting routing when performance shifts, and staying ready to bring in new models as they prove their value.
At Clearly Local, this is exactly how we think about translation strategy for global brands. We help organizations move from single-model dependency toward orchestrated, accountable, and adaptive translation ecosystems—built around your content, your risk profile, and your markets.
If your current setup runs everything through one model, now is the right time to ask what you’re missing. We’d welcome the conversation.
Upgrade your translation strategy
Clearly Local helps global brands build translation strategies that scale—without sacrificing quality, control, or flexibility.
Click here to learn more.
FAQs
AI translation orchestration is a system-level approach where multiple translation engines are coordinated through a central layer that automatically routes each piece of content to the most appropriate model based on factors like language pair, content type, quality requirements, and risk level, enabling more efficient and optimized global content workflows.
A single AI model is not enough because no model performs equally well across all languages, content types, and contexts, meaning that relying on just one creates trade-offs in quality, limits language coverage, increases risk from model changes, and prevents organizations from optimizing translation performance for different use cases.
Multi-model translation works by using an orchestration layer or system that evaluates incoming content and dynamically assigns it to the most suitable AI model—or even multiple models in parallel—based on predefined rules or performance criteria, sometimes combining outputs to improve accuracy and consistency.
Translation orchestration improves quality, reduces costs, mitigates risk, enables better compliance and auditability, and ensures that human expertise is applied where it adds the most value, allowing organizations to scale global content more effectively and strategically.
Companies choose the right AI model by evaluating factors such as language coverage, content type (e.g., marketing vs. technical), accuracy requirements, cost, data security policies, and past performance, often relying on orchestration systems to make these decisions dynamically rather than selecting a single model upfront.
The future of AI translation for global brands lies in flexible, multi-model ecosystems where orchestration, continuous benchmarking, and human-in-the-loop processes work together, enabling companies to adapt quickly to new models, maintain quality at scale, and treat translation as a strategic capability rather than a fixed tool.

