
Data, not models, is now the differentiator. That’s the industry consensus quietly building over the past year. In 2026, this reality is clearer than ever, with millions of models and barely any difference between the top 10. Your moat is now the quality of your training data.
But if you’re aiming to deploy AI across global markets, how you source this data matters. Scraped web content and synthetic data may seem like efficient shortcuts, but they come with hidden costs: embedded biases, cultural blind spots, and an erosion of the nuance that makes AI actually useful in the real world. To preserve your moat and grow market share, build your AI on data from the population it’s meant to serve: humans.
The Limits of Synthetic and Mined Data at Global Scale
Synthetic data and web scraping offer desirable benefits like being cheaper and faster to scale. And to be fair, synthetic data has its place. It can fill gaps in edge cases when real data is limited, or protect privacy by not using real individuals’ data. But when organizations rely too heavily on these approaches, especially at global scale, the cracks begin to show.
Scraped data from the web inherits whatever biases and gaps exist in its sources. If certain languages or cultural perspectives are underrepresented online, they’ll be underrepresented in your model. (To get a sense of this mismatch, check out the graph below.)

Share of global web content by language.
Synthetic data, meanwhile, is limited to the knowledge it was trained on. It can’t invent cultural context it has never seen, or detect speech formality levels in a language it barely knows.
And when synthetic data is generated from models that were themselves trained on synthetic data, the result is a feedback loop that researchers call “model collapse”, where each generation drifts further from reality, producing increasingly homogenized and less useful outputs.
For enterprises, this isn’t an abstract concern. Poor data quality costs them at least USD $12.9 million a year on average, according to Gartner. The higher the stakes (especially in specialized fields like healthcare), the more costly these failures become.
What Human-Created Training Data Really Means
Human-created training data is original content produced by people specifically for the purpose of teaching AI. It’s not scraped from the internet or generated by another model. It’s text, speech, annotations, and decisions made by real people who understand the context, intent, and consequences of what they’re creating.
In practice, this might mean native speakers writing examples of customer service conversations in their language, or domain experts labeling medical images with the precision required for diagnostic AI.
What makes human-created data distinctive is intentionality. Unlike machines, humans don’t just produce statistically plausible text; we encode how people think. We bring traits like ambiguity and creativity that machines can mimic but not originate. And that intentionality is what separates AI that works from AI that just looks like it should.
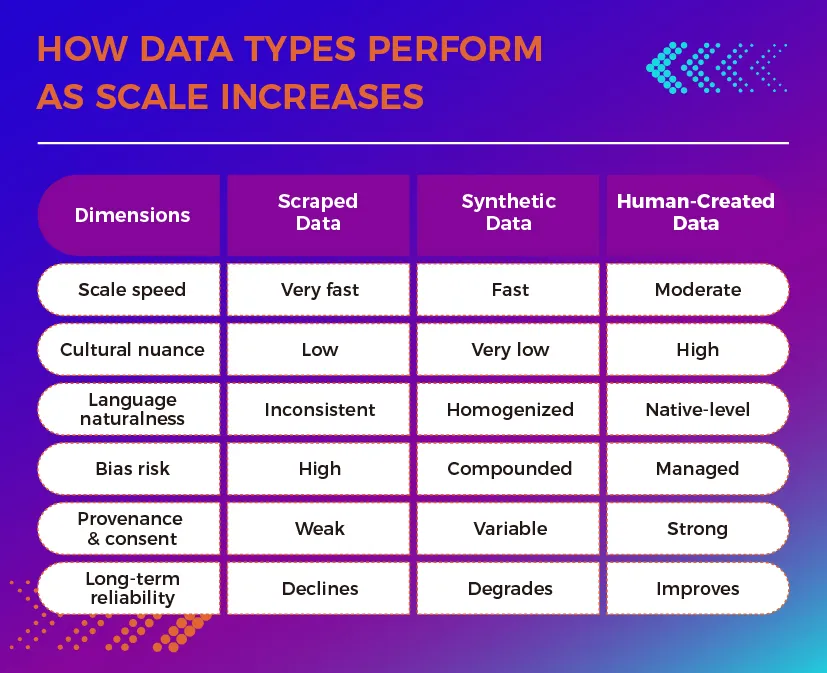
Why Human-Created Data Is Critical for Linguistic Accuracy
Language is never just words. It’s idioms, humor, implication, regional variation, and social context. A native speaker naturally encodes all of this when they write or speak. They know which phrases sound formal versus casual, or which words have meanings that shift depending on context.
Contrast that with translated or machine-generated text. Even when grammatically correct, it often sounds unnatural, slightly off in ways that native speakers immediately recognize. AI trained on this kind of data may pass basic comprehension tests, but it fails in real-world application.
For enterprises operating internationally, this is more than a user experience problem. It’s a trust issue. Users can tell when they’re interacting with AI that doesn’t truly understand their language.
For example, evaluations of ChatGPT show that while the model produces grammatically correct Modern Standard Arabic, native speakers immediately recognize the output as non‑native due to unnatural word choice and rigid, textbook‑like phrasing. The language is intelligible, but it doesn’t sound like something a native speaker would say.
In practice, this turns AI language limitations into a trust issue, not a user experience issue, because users conclude the system doesn’t truly speak their language.
Capturing Cultural Context and Intent Through Human Creation
Language and culture are inseparable. Humans embed cultural assumptions, values, and social norms into every sentence they write. AI trained without cultural awareness makes predictable errors. For example, some models trained using English synthetic and scraped content translated into Southeast Asian languages know more about hamburgers and Big Ben than local foods or landmarks. Cultural context is lost, even when grammar is correct.
Given the importance of cultural nuance in shaping business relationships—something 91% of CEOs say is critical to global success—it’s critical to get this right.
Human creators bring the cultural intelligence that AI cannot derive from patterns alone. They provide the necessary cultural context, so users feel like they’re talking to another native speaker. These are the kinds of insights that ensure your AI doesn’t just speak the language but sounds like it belongs there.
Human Data as a Model for Real-World Reasoning
A critical but often overlooked aspect of human-created data is that it reflects how people actually think and reason, including all the messiness that comes with it. Human language is full of ambiguity, implied meaning, and context-dependent interpretation. People contradict themselves. They change their minds mid-sentence. They rely on shared background knowledge that isn’t explicitly stated.
AI trained exclusively on clean, structured, or synthetic data struggles with this kind of real-world reasoning. It expects clarity and consistency. A 2025 OpenAI study shows that when inputs, including training data, are ambiguous or under‑specified, language models are incentivized to guess, often producing confident but incorrect answers instead of asking for clarification.
This becomes a serious problem in enterprise contexts where the “correct” answer depends on interpreting intent, not just matching keywords.
Human-created training data teaches AI how to handle these situations. It provides examples of ambiguous questions and how humans resolve them. It models the kind of contextual reasoning that distinguishes between “Can you send me that file?” (a polite request) and “Can you send me that file?” (an expression of doubt). It captures the kinds of unusual scenarios that rarely appear in scraped datasets but happen constantly in the real world.
Scraped data gives you volume. Human data gives you judgment. And for AI systems deployed in high-stakes environments, judgment is what determines whether the system is trustworthy or just statistically plausible.
Trust, Accountability, and Data Provenance
As global AI regulations increasingly hold organizations accountable for data quality and governance, the ability to demonstrate the origins of your training data is becoming a compliance necessity.
Human-created datasets offer something that scraped or synthetic data often cannot: clear provenance and documented intent. When data is created specifically for AI training, organizations can track where it came from and how it’s licensed and used. This becomes critical when regulators ask questions like “Can you prove this data was used with proper consent?” or “How do you know this dataset doesn’t violate copyright?”
The consequences of poor data provenance are real. In the U.S., for example, the Federal Trade Commission has already required companies to delete entire AI models when they couldn’t demonstrate valid user consent for training data. In Europe, the EU AI Act imposes strict requirements on data governance and transparency. Organizations that can’t trace their data sources face serious legal and financial risks, including being forced to rebuild models from scratch.
Human-created data, when properly managed, supports accountability. It allows enterprises to respond to audits, comply with regulations, and build AI systems that all relevant stakeholders can actually trust. In an environment where data provenance is becoming a competitive advantage, this clarity is invaluable.
Long-Term Enterprise Impact of Investing in Human Training Data
AI models are not static. They require ongoing refinement as language evolves, business contexts shift, and user expectations change. Organizations that invest in high-quality human training data build a durable asset, not just a one-time input.
Models trained on rich, human-generated data tend to generalize better. They handle novel situations more gracefully. They require less frequent retraining because the underlying patterns they’ve learned are rooted in genuine human behavior rather than artifacts of a particular dataset. Over time, this lowers total cost of ownership while improving reliability and adaptability.
In contrast, models trained primarily on synthetic or mined data often suffer from what researchers call “model drift”, where performance degrades over time as real-world conditions diverge from training conditions. Correcting this requires continuous data refinement. When your foundation is weak, maintenance becomes expensive and ongoing.
Human training data also enables organizations to build institutional knowledge into their AI. These datasets become strategic assets that competitors cannot easily replicate. In a world where AI models themselves are commodities, proprietary, high-quality data is one of the few remaining moats.
The upfront investment in human-created data pays dividends in accuracy, resilience, and scalability. It’s the difference between building AI that works today and building AI that continues to work tomorrow.
Conclusion: Human-Created Data as the Foundation of Global AI
As AI becomes ubiquitous and model capabilities converge, differentiation increasingly comes down to data. Global, multilingual AI only works when it reflects how real people think and behave. And that requires data created by humans.
This is where Clearly Local comes in. We help organizations build and scale human-led data pipelines to produce data that reflects real human behavior at scale.
Ready to build AI on data created by real people? Talk to Clearly Local about scaling human‑created data for your global AI systems.

