
We’re living through an AI revolution that’s transforming how global companies communicate with customers across languages and cultures. From automated translation to AI-powered customer support in dozens of languages, the promise is exhillarating: reach every market, speak every language, scale infinitely.
But the reality is the more we rely on AI for multilingual work, the more we encounter a stubborn quality gap. Machine translations that miss cultural nuance. Chatbots that sound fluent but feel robotic and contextually tone-deaf. The technology has advanced dramatically, yet something fundamental is still missing.
The culprit? AI data quality. Or more precisely, the lack of high-quality, culturally diverse multilingual data for AI systems to truly understand and generate multilingual content that resonates. Closing this gap is the key to maximizing AI ROI. And the organizations best positioned to help you fill it are Language Service Providers (LSPs), who’ve been quietly mastering the craft of cross-cultural communication for decades.
The Data Scarcity Problem in Multilingual AI
Data is the lifeblood of AI progress, and its scarcity is shaping the future of the industry. For the past few years, companies like Meta, Anthropic, and OpenAI have scraped nearly all available human-generated content from the internet in the race to build AGI and the most advanced AI systems. Neema Raphael, Goldman Sachs’ head of Data Engineering, recently summed up the situation bluntly: “We’ve already run out of training data.”
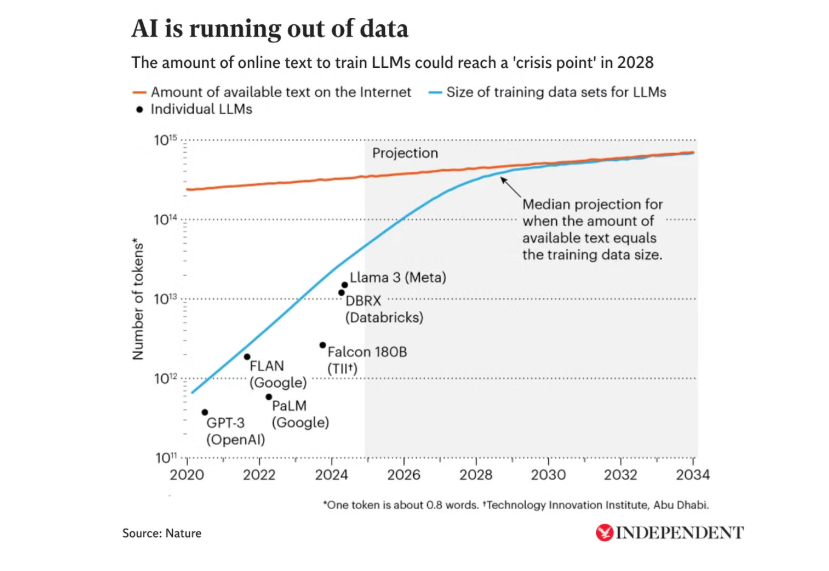
Shockingly, human-generated content has plateaued, while synthetic content is exploding, much of it low-quality “AI slop.” Several 2025 analyses estimate that more than half of all web-based text is now AI-generated, with projections suggesting that figure could reach 90% by 2026. Faced with this reality, some companies are experimenting with synthetic data to train models. But as Raphael observed, the quality of output depends on the quality of input. If synthetic slop becomes the dominant training source, creativity will stagnate. Elon Musk also warned earlier this year that over-reliance on synthetic data risks “model collapse,” where outputs degrade over time.
So, there is still a consensus among experts that human-generated data is still king. Yet even within that category lies a deeper challenge: not all languages have equal representation. Brad Smith, Microsoft’s Vice Chair and President, recently highlighted this imbalance at the Abu Dhabi Global AI Summit:
“Most content on the internet is in English, more than 60%, way out of proportion to the percentage of the world’s people that speak English. Arabic is underrepresented. You get to Swahili and other African languages, even more underrepresented. That’s a problem because generally, at this point, AI performs better when there is more data in a language to train it.”
This disparity explains why English accounts for over 90% of training data for most large language models. Meanwhile, thousands of the world’s 7,000+ languages—especially low-resource ones—have minimal online text available. Collecting vast, high-quality datasets for these languages is difficult and expensive. And without culturally nuanced, domain-specific multilingual data, AI systems struggle to deliver outputs that feel authentic, contextually appropriate, and trustworthy.
The result? Models that excel in English but falter elsewhere. For global companies, this technical limitation is a strategic risk and contributes to the reluctance to deploy AI at scale. Closing this gap requires more than scraping the web. It demands partnerships and processes that create, validate, and refine multilingual data at scale.
Language Service Providers: The Untapped Data Foundries
Here’s where the story gets interesting. While tech companies have been racing to build bigger models, there’s been an entire industry perfecting the art and science of multilingual communication: Language Service Providers (LSPs).
LSPs bring capabilities that are extremely valuable in the AI era. They employ thousands of native-speaking linguists to adapt meaning across cultural contexts. They’ve built sophisticated quality assurance workflows that catch the kinds of subtle errors machines routinely miss. They understand domain-specific terminology, regional variations, and the countless ways that language functions differently across markets.
LSPs are data creators in the truest sense, generating, validating and refining multilingual content every single day. Think of them as “data foundries,” transforming raw linguistic material into refined, high-quality datasets that can power AI systems.
This human-in-the-loop expertise is exactly what AI training pipelines need but often lack. LSPs can curate multilingual datasets tailored to specific industries, validate AI outputs for cultural appropriateness, and provide the kind of nuanced feedback that helps models learn not just what’s grammatically correct, but what actually works in real-world contexts. They can identify edge cases, flag cultural sensitivities, and ensure that training data represents the genuine diversity of how languages are used across different markets and demographics.
In essence, LSPs are sitting on—and continuously generating—the exact resource that’s becoming increasingly valuable in the AI economy: high-quality, contextually rich, culturally validated multilingual data. This is the foundation of trustworthy AI.
Strategic Implications for Global Companies
Our own experience shows that smart global companies are beginning to recognize this opportunity and rethink how they approach multilingual AI. Rather than viewing LSPs as traditional service vendors, they’re exploring strategic partnerships that position LSPs as data partners and quality gatekeepers.
The possibilities of working with LSPs span the full data lifecycle:
- Data Collection: LSPs leverage their global networks to collect diverse, targeted, and high-quality raw data (text, speech, images, or video) to ensure AI models are trained on real-world, culturally appropriate content from specific locales.
- Data Creation/Generation: This involves creating new content where none exists, such as generating multilingual copywriting, specific conversational prompts, and adversarial responses to test and fine-tune Generative AI models for bias and robustness.
- Data Annotation/Labeling: This is the process of applying high-quality labels to raw data to make it machine-readable for AI training. For language, this includes tasks like Named Entity Recognition (NER), sentiment analysis, and intent annotation.
- Data Evaluation/Validation: LSPs provide the crucial “human-in-the-loop” services to rigorously evaluate AI output, including prompt rating and ranking, fact-checking machine translations, and assessing model responses for accuracy, cultural relevance, and compliance.
- Model Training & Fine-Tuning: LSPs contribute directly to the final phase of model development by providing expert human feedback for Reinforcement Learning from Human Feedback (RLHF) and Supervised Fine-Tuning, helping models become more inclusive and align with specific brand voices and cultural norms.
Companies that build strong data partnerships with LSPs can create proprietary datasets that become strategic assets: moats competitors can’t easily cross. These partnerships give organizations the confidence to scale AI across operations, knowing outputs are created and validated through rigorous human-in-the-loop processes. In a world where only 46% of people trust AI systems, these capabilities are key to maximizing AI ROI and global growth.
Building the Future of Trustworthy Multilingual AI
The companies that will win in global markets aren’t those with the biggest AI models or the most languages on paper. They’ll be the ones who’ve invested in the data foundation: the curated, validated, culturally grounded datasets that make AI systems genuinely useful across cultures.
This requires a shift in perspective. View your LSP relationships not as transactional vendor arrangements, but as strategic partnerships that can unlock competitive advantage. Invest in joint data initiatives. Build collaborative workflows where human linguists and AI systems complement each other. Create proprietary multilingual datasets that become strategic assets.
The future of multilingual AI won’t be built by technology alone. It will be forged in the data foundries where linguistic expertise meets scalable processes, precisely where LSPs have been operating all along.
Don’t just invest in multilingual AI; make it trustworthy and effective. Build the data infrastructure that drives ROI. Discover how at Clearly Local.

